
|
|
Библиотека Интернет Индустрии I2R.ru |
||
Page Promoter 7.1: считайте на русском с намиВы никогда не спрашивали себя, почему такие поисковые машины, как, например Google или Yahoo, несмотря на огромную популярность в англоязычных странах, заметно проигрывают в популярности отечественным Яндексу и Рамблеру? Ведь, казалось бы, тот же Google, с его восемью миллиардами проиндексированных страниц, должен давать больше точной и нужной информации в ответ на тот или иной поисковый запрос. Но этого не происходит. И проблема не в самой поисковой машине или ее алгоритме ранжирования – ведь общепризнанным фактом является тот, что у Гугла один из лучших алгоритмов – а проблема в понимании поисковой машиной языка. Нет, вы не подумайте, что Гугл совсем языка не понимает, если вы зададите слово «раскрутка», он вам и возвратит несколько сотен тысяч страниц, содержащих это слово. Но страницу, содержащую такую фразу как «правила раскрутки», он по данному запросу не возвратит, даже несмотря на то, что это будет, с пользовательской точки зрения, лучшая страница, соответствующая данному запросу. А вот Яндекс возвратит. И Рамблер тоже. В чем же загвоздка? Дело в том, что русский язык характеризуется флективностью, то есть, при образовании грамматических форм слово видоизменяется, приобретает окончания, суффиксы, иногда при этом изменяется также основа слова. Наука о видоизменении слова называется морфологией. Морфология, по определению Википедии, это грамматический учет слова, включающий в себя учение о структуре слова, формах словоизменения, способах выражения грамматических значений, а также о частях речи и присущих им способах словообразования. Вместе с синтаксисом морфология составляет грамматику. Вот именно морфология и составляет главную проблему для поисковых машин. Почему? Да все очень просто. Давайте представим себе, что два робота поисковых машин, скажем, тех же Яндекса и Гугла заходят на одну и ту же страницу, скажем, стартовую страницу сайта www.iru.ru. Разница в восприятии страницы двумя поисковыми машинами проявится уже в заголовке страницы, который выглядит так: «Ноутбуки iRU: Отличное соотношение цена/качество. Наш ноутбук - Ваш лучший друг! ( notebook Intro, Novia, Stilo, Brava)» Яндекс обнаружит два повторения слова «ноутбук» в заголовке, а Гугл – только одно, поскольку он «не понимает», что слова «ноутбук» и «ноутбуки» - это две словоформы, образованные от одной основы. Таким образом, частота повторения ключевого слова для Яндекса будет в два раза выше, чем для Гугла, а это уже существенная разница. Дальше-больше, Яндекс выдаст больше «правильных» страниц, Гугл же ввиду недостатка, а именно отсутствия понимания морфологии, выдаст их значительно меньше. Описание сайта в выдаче Яндекса:  Описание сайта в выдаче Гугла:  В принципе, во внедрении русской морфологии нет ничего принципиально трудного или невозможного – основные правила машинной обработки русских текстов были разработаны еще в конце восьмидесятых прошлого столетия и сейчас успешно используются такими поисковиками как Яндекс, Рамблер, Апорт и другими отечественными машинами. Если у вас возникла задача оптимизировать сайт под один из отечественных поисковиков (или все сразу), как же узнать по какому алгоритму они (русские поисковики) считают слова на странице? Велосипеда выдумывать не стоит, как я уже упомянул, успешных решений проблемы морфологии существует несколько, и все поисковые машины, учитывающие морфологию, считают слова более-менее одинаково. И программа, которая может анализировать страницы подобно поисковым машинам, уже существует – совсем недавно компания NetPromoter выпустила новую версию программы Page Promoter 7.1, которая может анализировать страницы по тому же алгоритму, что и «морфологически грамотные» поисковики. Подход состоит в том, что в данной программе использован м орфологический анализатор русского языка одного из ведущих российских разработчиков лингвистических технологий Андрея Коваленко. Достаточно будет перечислить предыдущие внедрения ранее разработанных им технологий - Апорт, МедиаЛингва, Рамблер, МЕТА, АРБТ, Консультант+. Анализатор страниц, используемый в программе, распознает более четырех миллионов различных словоформ, используя наиболее полный грамматический словарь объемом в 156 тысяч слов, что покрывает практически весь активный словарь русского языка и принимает во внимание грамматическую информацию о них. Что тут и говорить, если словарный запас среднестатистического образованного человека составляет около 20 тысяч слов, а активный и то меньше. Вот как сам Андрей Коваленко прокомментировал сложившуюся ситуацию: 
«Меня всегда удивляло, почему многие отечественные компании-разработчики программного обеспечения, столкнувшись с какой-либо проблемой, вместо очевидного, даже неискушенному в данном вопросе человеку решения, – обращения к специалистам – зачастую начинают изобретать велосипед сами. Казалось бы, ни для кого не секрет, что монтаж водопровода стоит доверить сантехнику, а выпечку хлеба – пекарю! В результате самостоятельного решения такого рода вопросов, как правило, на выходе получается либо срыв сроков (см. Правила Ашманова), либо нечто колченогое, либо оно же, но еще и со срывом сроков проекта. Поэтому сотрудничество с компанией NetPromoter доставило мне огромное удовольствие. Я оценил действительно высокопрофессиональный подход менеджеров, с которыми довелось пообщаться, грамотный подход к бизнесу лично Сергея Баирова, а также высокую квалификацию и заинтересованность разработчиков, с которыми мне довелось общаться по ходу встраивания морфологического анализатора в их разработку: действительно, сотрудники компании подробнейшим образом вникали во все тонкости работы с предложенной технологией, задавали грамотные вопросы и даже, проведя глубокое тестирование, указали на ряд неточностей в описании словоизменения нескольких слов. Компания NetPromoter в этой разработке использовала самый правильный путь – максимальное приближение структуры модели к структуре оригинала, чтобы получить наиболее точную интерполяцию поведения оригинала – поисковой системы. Таким образом, становится возможным исследование влияния текстовых критериев на ранжирование документов.» Давайте посмотрим, как программа справляется с обработкой русского текста. Для сравнения возьмем два отчета по анализу одной и той же страницы – один без учета морфологии, а другой – с учетом. Сгенерированы оба программой Page Promoter на основе страницы сайта www.iru.ru. Без учета морфологии:  С учетом морфологии: 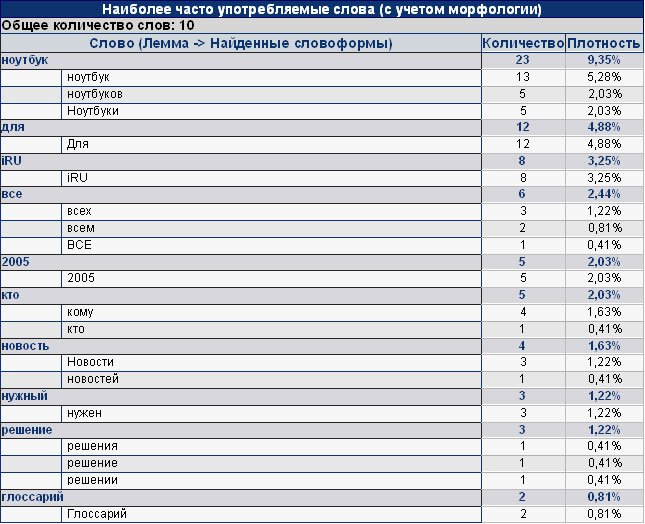 Как вы видите из приведенных отчетов, во втором случае программа сводит все словоформы к одной основе. Набор словоформ в программе (и в компьютерной лингвистике) называется леммой. Программа точно распознает все слова, образованные от слова, например, «ноутбук» - «ноутбуки», «ноутбуков». При этом статистика выводится как по всей лемме, так и по отдельным словоформам, в результате чего мы имеем частоту ключевого слова «ноутбук» равную 9,35%, в то время как при первом типе анализа данное слово составляет 5,96%, то есть почти в два раза меньше. Таким образом, я думаю, любой оптимизатор даже с минимальным опытом работы понимает цену такой ошибки. Мы могли бы, естественно, привести много примеров, но, думаем, что читателям будет интереснее попробовать самостоятельно, поскольку контраст настолько разителен, что вряд ли нуждается в объяснениях. На наш взгляд, время программ, которые не учитывают морфологию, а таким образом, не эмулируют действие поисковых машин и изначально выдают погрешность, часто критическую, осталось в прошлом.  Свое видение ситуации изложил Владимир Поляков, доцент МИСиС и МГЛУ, член Российской ассоциации искусственного интеллекта, член Ассоциации когнитивной славистики (США), автор многочисленных сетевых публикаций на тему поисковых технологий, инициатор проекта "Интеллектуальная поисковая машина" (проект удостоен гранта Российского Фонда Фундаментальных Исследований): «Надо сказать, что программа Page Promoter и без русской морфологии представляла собой превосходный инструмент по оптимизации, продвижению и аудиту сетевых ресурсов. С появлением версии 7.1 вопрос о лидерстве в этом сегменте рынка отпал, по-моему, сам собой. Мощный функционал и база данных программы были подкреплены высокопрофессиональной разработкой Андрея Коваленко. Про Андрея Коваленко отдельный разговор. Это признанный корифей в такой сложнейшей сфере, как разработка морфоанализаторов. Причем задача компьютерной реализации морфологии русского языка сложна со всех точек зрения: технологической, инженерной и научной. Не надо думать, что достаточно завести пару словарей в базу данных и задача будет решена. Мне известны, например, несколько фирм, проекты которых в Сети просто не пошли в силу того, что они слишком легкомысленно подошли к этой проблеме, набрали новичков, не изучили опыта "предшественников". Таких специалистов, как Андрей, пожалуй, во всем мире можно пересчитать просто по пальцам одной руки. Я рад, что NetPromoter остановил свой выбор именно на его разработке. Это говорит о высоком уровне бизнес решений в компании. Пользуясь случаем, скажу пару слов и о программе Page Promoter. Программа предоставляет разработчику и администратору сайта решение извечной сетевой проблемы - как быть первым среди себе подобных. Люди тратят на решение этой проблемы массу сил и времени. Здесь же искусство продвижения сайта сведено до уровня ремесла. Наверное, так и должно быть на рынке - "плати адекватную сумму и получи качественное решение". Я испытал программу на собственном сайте www.sowsoft.com/rubryx, который посвящен классификации текстов. В этой сфере работают тысячи компаний, среди которых такие гиганты как IBM, Reiter, SAS. Сейчас сайт на поисковой системе Google по одному из основных для меня запросов стабильно попадает в первую десятку. А в настоящее время вообще находится на первом месте.» Материалы по теме: Автор: Денис Кравченко |
|
| 2000-2008 г. Все авторские права соблюдены. |