Я мыслю, следовательно, раскручиваю
Автор: Александр Садовский, «Исследования и статистика» (http://digits.ru/).
Написано в ноябре 2001. Статья с небольшими изменениями опубликована в журнале Chip, номере за январь 2002. Последнюю версию этой статьи вы всегда можете найти по адресу http://digits.ru/articles/promotion/se_promotion.html.
Всегда выбирайте самый трудный путь —
там вы не встретите конкурентов. Шарль де Голль
Согласно исследованию японских ученых, люди, пользующиеся компьютерами каждый день, к тридцати годам практически полностью теряют способность что-либо запоминать.
Корзина с фактами
- От 75% до 85% пользователей, согласно разным исследованиям, ищут сайты, используя поисковики
- 57% пользователей занимаются поиском каждый день
- Средний американец тратит 1,5 часа в неделю на поиск информации
- Средний бизнесмен тратит 73 минуты в месяц на использование поисковиков
- Пользователи при поиске продуктов наиболее вероятно обратятся к поисковикам (28%)
- Пользователи бросают поиски после 12 минут бесплодных попыток
- Около 75% пользователей разочаровываются при поиске информации в Интернете
- Поисковики генерируют 7% трафика веб-сайтов
- Американцы готовы платить около 14,5 долларов в неделю за возможность находить ответы на свои вопросы. При этом средний американец нуждается в ответе на 4 вопроса каждый день
|
Катастрофа? Жизненное фиаско? Вовсе нет, им приходят на помощь поисковые машины: если что-то нельзя вспомнить, это можно найти. Эта горстка сайтов, любовно называемая поисковиками и искалками, играет огромную роль в современном мире. Достаточно взглянуть на врезку «Корзина с фактами», чтобы понять, что многие из нас уделяют времени поисковикам значительно больше, чем своей жене и детям. Эта статья — еще один шанс немного обделить вниманием близких людей для тех, кто мечтает о толпах посетителей в гуще своего сайта.
Рассказать о поисковиках непросто — в этом безумном мире запросов и ответов информация устаревает едва ли не в момент появления. Поэтому я попытаюсь избежать советов «как надо сделать, чтобы...» Надо учиться искать и думать. Где искать, что искать и о чем думать — да, вы угадали, именно этим вопросам посвящена статья.
Что такое успешная оптимизация?
Цель оптимизации сайта — получить максимум целевых посетителей, то есть тех, которые что-то купят, заполнят анкету или заинтересуются темой сайта. Как достичь этого? Давайте думать.
Если сайт нацелен на какой-то регион, логично сделать упор на местные поисковики. При этом выбор поисковика резонно делать на основе его посещаемости, которую можно узнать из рейтингов MediaMetrix и Nielsen/NetRatings, а в русскоязычном Интернете — Rambler's Top100, Рейтинг@mail.ru (бывший TopList) и SpyLog.
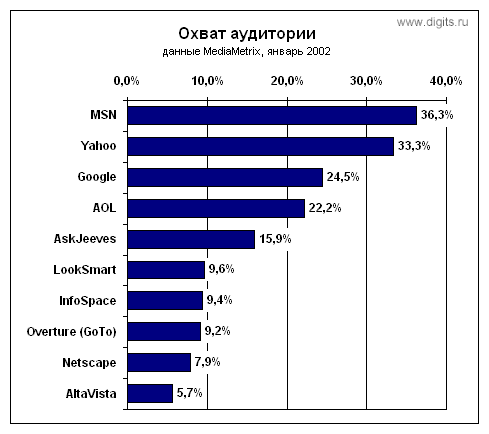
Впрочем, и тут не обошлось без подводных камней. Взгляните на рейтинг MediaMetrix: кажется, что Google — не лучший выбор для раскрутки сайта.
Но давайте думать. Из таблицы альянсов поисковиков обнаруживается, что кроме своего сайта Google присутствует на Yahoo и Netscape, а это уже сила.
Таблица альянсов
| Сайт |
Чей поиск использует |
| Основные результаты |
Вторичные результаты |
| AltaVista |
Собственный поиск |
LookSmart |
| Ask Jeeves |
Ссылки собственных редакторов |
Direct Hit |
| AOL Search |
Open Directory |
Inktomi |
| Direct Hit (собственность Ask Jeeves) |
Собственная база |
Open Directory |
| Excite (владеет WebCrawler) |
Собственный поиск |
LookSmart |
| FAST (владеет AllTheWeb; Lycos — инвестор FAST) |
Предоставляет свой поиск другим сайтам |
— |
| HotBot (собственность Lycos) |
Direct Hit |
Inktomi
Open Directory |
| Inktomi |
Предоставляет свой поиск другим сайтам |
— |
| iWon |
Inktomi |
LookSmart
Верхние 10 результатов из Direct Hit |
| Google |
Собственный поиск |
Open Directory |
| GoTo (Overture) |
От рекламодателей |
Inktomi |
| LookSmart (каталог) |
От собственных редакторов |
Inktomi |
| Lycos |
Open Directory
FAST |
Некоторые «популярные» результаты из Direct Hit |
| MSN Search (собственность Microsoft) |
От собственных редакторов и из LookSmart |
Inktomi
Верхние 10 результатов из Direct Hit |
| Netscape Search (собственность AOL) |
Open Directory |
Google |
| Northern Light |
Собственный поиск |
— |
| Open Directory (каталог, собственность AOL) |
От собственных редакторов |
— |
| Yahoo |
От собственных редакторов |
Google |
По информации SearchEngineWatch на 2001 год
|
Следовательно, выбирая поисковик, нужно смотреть не только на посещаемость, но и на тех, кто использует его механизм поиска. Получается, что для целей оптимизации стоит исследовать максимум 5-7 поисковых механизмов: Google, Inktomi, AltaVista, FAST и др., а среди русскоязычных — Яндекс, Рамблер и Апорт.
Оценивая позицию в результатах поиска, помните, что около 60% пользователей ограничиваются первой страницей результатов поиска, и почти 90% — первыми тремя. Поэтому место ниже 30, как правило, не результат, хотя по самым популярным запросам оно может давать сотни посетителей.
Алгоритмы
Откуда брать информацию об алгоритмах?
Если алгоритмы поиска станут известны всем, тут же появятся «идеальные» странички, про которые поисковик подумает «До чего ж хороши!» и поставит их на первые места вместо страниц, которые ожидал найти пользователь. Отсюда ясно, что никогда, нигде ни один поисковик не откроет своих настоящих алгоритмов, за исключением трех случаев:
- Публикация научных статей.
- Когда информационная закрытость компании противоречит целям рекламы или «public relations» (спрашивайте сотрудников поисковиков на форумах и читайте их интервью).
- Когда маленькие человеческие слабости — желание поделиться информацией с другом или похвастаться достижениями поисковика на форуме — берут верх.
Откуда еще можно брать информацию? Давайте думать.
- Исследования и эксперименты других специалистов обычно описываются в статьях, пресс-релизах, на форумах.
- Статистические и аналитические сайты, казалось бы, не имеют отношения к методике оптимизации. На практике же они могут дать очень много информации, скрываемой поисковиками — кто ищет, где, какие запросы задает, как часто и т. д., что может существенно облегчить раскрутку сайта.
- Ваши собственные эксперименты — об этом чуть ниже.
А мне недавно сказали...
Когда кто-то говорит о новом факторе ранжирования, часто следует вопрос: правда это или нет? Давайте думать. Чтобы ответить на него, нужно знать, к чему стремятся алгоритмы поиска, какая у них цель и какие проблемы.
Эффективность поиска принято оценивать по двум основным критериям: полноте и точности. Чем больше процент релевантных (соответствующих запросу) документов среди всех найденных, тем выше точность. И чем больше найдено релевантных документов среди всех, что хранятся в базе поисковика, тем лучше полнота. Основная же проблема — ресурсоемкость поиска (нужно хранить много данных и до-о-о-олго их обрабатывать).
Следовательно, если «новый фактор ранжирования» может улучшить показатели точности или полноты, не вызвав резкого увеличения потребности в ресурсах, он правдоподобен. Например, именно из-за затрат времени не индексируются JavaScript-код и Flash, хотя технически реализовать и то, и другое не так уж сложно.
«Пора в путь-дорогу...»
С точки зрения оптимизации сайта у крупного поисковика существует три основных источника информации для вычисления релевантности страницы: 1) содержание страницы и сайта, 2) другие веб-сайты, 3) поведение пользователей. Если первым источником легко манипулировать, второй поддается только ограниченному воздействию, то влиять же на третий крайне сложно. Поэтому поисковики придают большой вес последним двум источникам.
Оптимизируя сайты, всегда проговаривайте про себя вопрос: «Как поисковик будет действовать в момент запроса?», очень часто это помогает найти новые решения. Простой пример. Когда пользователь задает слово запроса строчными буквами, Яндекс находит все вхождения слова, независимо от его регистра; но если слово написано с прописной буквы, Яндекс будет искать только такие варианты. Следовательно, начиная с прописной буквы в тексте страницы все слова, которые пользователь часто пишет с большой буквы, вы повышаете вероятность нахождения страницы по всем видам данного запроса.
Содержание страницы и сайта
Текст страницы
Поисковик интересуется, прежде всего, тем, насколько часто встречается слово из запроса в документе по сравнению с другими словами. Если слов в запросе несколько, то вес каждого из них тем больше, чем в меньшем количестве документов базы оно содержится. В то же время, страница со слишком часто встречающимся словом запроса считается спамом, и ее позиция в результатах поиска заметно понижается.
Каким образом следует выбирать ключевые слова для оптимизации? Давайте думать. Во-первых, чем чаще их запрашивают, тем лучше. Во-вторых, чем меньше конкурирующих сайтов, тем легче добиться хорошей позиции. В-третьих, так как вес слова тем больше, чем реже встречается оно в других документах, то при оптимизации под запросы из нескольких слов выгодно делать упор на редкие слова.
Теги и мета-теги
Откуда пошли мифы про чудодейственную силу мета-тегов? Из истории поисковиков. Когда поисковики были маленькими, а веб-мастера неопытными, кто-то подумал: а зачем городить эти сложные алгоритмы вычисления релевантности, если можно попросить веб-мастеров описать словами в специальных тегах их сайт? Уж человек-то наверняка разбирается в том, какие темы его сайт охватывает! Возможно, первое время так и было. Веб-мастера скромно писали в мета-тегах «личная страничка, Вася, Пупкин, кошка Люся» и были счастливы, видя свой сайт вверху результатов поиска по запросу «кошка Васи Пупкина». Но прошло время, веб-мастера узнали, что такое баннер и как его можно продать, и началось: «рефераты рефераты рефераты». Наивные поисковики стали находить по слову «рефераты» все, что им предлагали. В итоге, сегодня Рамблер не учитывает мета-теги совсем, Яндекс — только если соответствующие им слова часто встречаются в тексте страницы, и Апорт незначительно поднимает вес страницы при совпадении запроса со словом из мета-тега.
Alt-теги изображений учитывают далеко не все поисковики, но некоторые к ним внимательно прислушиваются, так что забывать о них не стоит.
Но есть один особенно важный тег — это тег <title> заголовка страницы. В отличие от мета-тегов, пользователь его видит на экране, поэтому поисковик придает <title> большое значение.
Что нужно делать с тегами? Давайте думать. Даже если мета-теги влияют на один поисковик из десяти, поставить их стоит — это дело одной минуты. Выберите самые популярные слова со страницы, которые совпадают с ключевыми, и внесите их в мета-теги. В title желательно из этих слов составить нормальный заголовок.
Положение слов на странице
Когда на запрос «свободная экономическая зона» находятся тексты о переполнении зон из-за экономической ситуации, это значит, что поисковик не учитывает близость слов в тексте. Это плохой поисковик. Большинство современных искалок отдают приоритет совпадению фраз и стараются найти документы, где слова стоят как можно ближе друг к другу.
Многие поисковики учитывают расстояние от начала страницы до слова, считая, что в начале чаще располагается важная информация.
Как оптимизировать с учетом этих данных? Давайте думать. Во-первых, при оптимизации под запрос из нескольких слов соответствующие слова в тексте нужно располагать как можно ближе друг к другу. Во-вторых, начинайте страницу с самых важных слов.
Оформление
Когда страница встречает заголовком с буквами таких размеров, что возникают сомнения, поместится ли здесь что-то еще, можно предположить, что информация в таком заголовке очень важная. Поэтому поисковик придает дополнительный вес словам, расположенным в заголовках (<h1>...<h6>), тегах <strong>, <em>, <b>, <i> и др.
Как же это использовать? Давайте думать. Во-первых, надо как можно чаще использовать эти теги для важных слов. Во-вторых, если вспомнить о CSS (каскадные таблицы стилей), то обнаружится, что большинство поисковиков не интерпретируют информацию CSS (подумайте, почему), и даже когда половина текста будет набрана заголовком <h1>, переопределив вид тегов в CSS, можно получить красивый и опрятный дизайн.
Сайт в целом
Представьте себе переборчивого жениха, который никак не может отыскать невесту с нужными характеристиками, скажем, интеллигентную. Вот эта, кажется, подходит, но родители у нее землекопы; а вон та, похоже, интеллигентная, но, беря пример с брата-уголовника и отца-депутата, она, думает парень, вряд ли останется такой. Тогда жених определяет для себя: если все родственники у невесты, как и она сама, интеллигентны, значит подходит. Примерно так же рассуждает поисковик, когда дает приоритет тем сайтам, на которых больше число страниц, соответствующих запросу. В чем-то это верно, когда речь идет про интеллигентность, но если нужно выбрать невесту с длинными волосами, то коротко остриженные родственники, на мой взгляд, не должны быть помехой.
Как лучше оптимизировать сайт? Давайте думать. Чем больше страниц на сайте, включающих слова запроса, тем больше вес каждой из них. Следовательно, надо увеличивать число страниц как можно больше. Этот совет имеет еще два плюса: во-первых, при грамотном использовании ссылок можно существенно увеличить вес сайта по алгоритму PageRank, во-вторых, возрастает вероятность случайного захода на страницу. Для умеренно популярной темы тысяча русскоязычных страниц безо всякой оптимизации приносят до 40-70 случайных посетителей с каждого поисковика, который проиндексировал сайт.
Тема сайта
Некоторые поисковики стараются определить тему сайта, и если она не совпадает с темой запроса, то такой сайт даже не рассматривается. Как избежать такого? Давайте думать. Алгоритмы, определяющие тему сайта, как правило, исследуют слова, присутствующие на странице, сравнивая их со словами, часто встречающимися для данной темы. Следовательно, если изучить частоты слов из десятка текстов на интересующую вас тему, и увериться, что все самые популярные слова есть на страницах сайта, то с темой будет полный порядок.
Хижина дяди Сэма
Есть вещи, которые покупаются редко или раз и навсегда: дом, неподкупный политик, домен для сайта. Логично предполагать, что покупатель не пожелает себе плохого, а постарается, чтобы приобретение соответствовало его вкусам и роду деятельности. Основываясь на этой догадке, поисковики придают дополнительный вес страницам, у которых домен или имя файла совпадают с ключевым словом. У многих искалок есть еще одно предпочтение — некоммерческие домены первого уровня (вроде edu и gov) и домен com.
И что же делать? Давайте думать. Домен не так важен, как кажется — достаточно взглянуть на результаты поиска, чтобы убедиться, что доменов, совпадающих с запросом, в первой десятке довольно мало. В то же время, когда можно задать имя файла, совпадающее с ключевым словом, не стоит игнорировать эту возможность.
Другие веб-сайты
PageRank
Подробное описание алгоритма вы можете найти в статье «Растолкованный PageRank».
Ссылочное ранжирование
Когда на сайт ссылаются десятки страниц словами «а эти козлы не вернули мне деньги», это, как правило, означает, что по ссылке действительно можно найти козлов. Правда, этот же сайт будет находится и по слову «деньги», что, в принципе, тоже верно, потому что деньги остались у козлов. Так вот, это и называется ссылочным ранжированием. Написать на своей странице можно что угодно, но когда на нее все ссылаются теми же словами, поисковик начинает доверять.
Что тут делать? Давайте думать. До того, как начнете регистрироваться в каталогах и обмениваться ссылками, выберите краткое название своего сайта, включающее слова, под которые он оптимизируется. Тогда, с большой вероятностью, ссылка будет выглядеть так, как вам хочется. Несмотря на простоту, алгоритм имеет огромное значение при вычислении релевантности, и ему нужно уделять самое пристальное внимание.
Присутствие в каталоге
Многие поисковики имеют при себе каталоги. Как они используют их?
- Сайт поднимается в результатах, если слова запроса совпадают с описанием из каталога. В некоторых искалках дополнительный вес сайту дает сам факт присутствия в каталоге, так как в него попадают ссылки только на качественные страницы.
- Если сайт отсутствует в каталоге, а пользователь ограничивает поиск какой-то темой (такое позволяет Яндекс), то даже при совпадении с темой сайта он показан не будет.
- Однословные запросы обычно навигационные (пользователь хочет не найти какой-то факт, а получить «что-то на эту тему»). И тут как нельзя лучше подходят сайты из соответствующей категории каталога. Посмотрите на выдачу Яндекса по популярным однословным запросам — сплошь главные страницы сайтов и сайты из каталога.
Как можно это использовать? Давайте думать. А что тут думать, регистрируйтесь!
Пользовательская оценка
Есть такая интересная система DirectHit. Ее идея оценки качества сайтов основана на предположении, что если пользователь переходит по ссылке, значит, он счел ее хорошей, и если долго не возвращается на страницу поисковика, значит, его ожидания подтвердились. Именно эти критерии — число переходов по ссылке, время нахождения на странице и возвраты к поисковику — легли в основу корректора релевантности, который DirectHit предлагает другим сайтам.
Рамблер до пяти первых сайтов в результатах поиска берет из рейтинга Top100 (а посещаемость — своего рода пользовательская оценка). У Яндекса есть «Популярные находки» — раздел, в котором отображаются сайты с относительно небольшой релевантностью, но часто выбираемые пользователями.
И что, совсем-совсем нельзя повлиять на это? Давайте думать. Повлиять можно. Представьте, на основе каких критериев пользователи решают перейти на сайт. Заголовок, раз. Описание, два. URL, три. Заголовки должны учитывать психологию восприятия (см. «13 замечаний Огилви о заголовках»). Что касается описаний, то поисковики берут их из мета-тега description или выдергивают из текста страницы отрывки со словами запроса. Позаботьтесь, чтобы такие отрывки привлекали внимание.
Спам
Если вы пробовали сунуть руку в пчелиный улей, то знаете, что это может быть больно. Теперь представьте обратную ситуацию: пчел в улее десяток-другой, а вот рук, тянущихся к меду, сотни тысяч. Естественно, что пчелы — сотрудники поисковиков — не любят спамеров! Пока есть масса легальных методов улучшить позицию страницы в результатах поиска, заниматься спамом, по-моему, не стоит, но знать о нем надо.
Какие виды спама бывают?
- Избыточное число ключевых слов на странице или в мета-тегах. Используется редко, потому что поисковики легко вылавливают такие страницы.
- Дорвей (doorway) — страница, нашпигованная ключевыми словами, которая, как только пользователь переходит на нее, тут же делает редирект — перенаправляет его на другой сайт. Встречаются дорвеи без редиректа, дающие пользователю возможность перейти на сайт или уйти. Корректно сделанный дорвей без редиректа является, по сути, обычной оптимизированной страницей и может не рассматриваться как спам.
- Невидимый или слабовидимый текст, цвет которого совпадает с цветом фона страницы, либо шрифт очень мелкий.
- Клоакинг (cloaking) — если известны IP-адреса индексирующих роботов поисковиков, можно выдавать пользователю одну страницу, а поисковику другую — усыпанную ключевыми словами. И хотя IP роботов постоянно меняются, ряд фирм продает свежие базы адресов.
Индексация
Как ускорить переиндексацию?
Чем чаще сайт переиндексируется, тем более свежая информация доступна пользователю при поиске и, самое главное, можно проводить значительно больше экспериментов по оптимизации. Как же ускорить переиндексацию? Давайте думать.
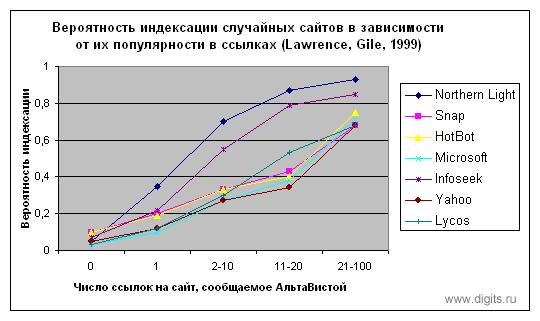
- Поднять вес страницы — Google и другие поисковики, использующие алгоритм PageRank, индексируют новые страницы в порядке убывания их весов, а страницы с большим весом чаще переиндексируют. Посмотрите на диаграмму — страницы с малым числом ссылающихся на них сайтов могут никогда так и не быть проиндексированы.
- Обновлять сайт регулярно. Поисковики стараются определить период обновления сайта, чтобы не приходить слишком часто.
- Заплатить деньги. Например, Inktomi обещает после оплаты переиндексировать сайт каждые 48 часов в течение года.
- Если сайт относится к СМИ, можно зарегистрировать его как новостное агентство. Сайты новостных агентств переиндексируются очень часто (Яндексом — каждые 15 минут).
- Переименовать страницы, которые нужно срочно переиндексировать, и добавить их в поисковик заново, а старые удалить. Работает только в тех случаях, когда поисковик индексирует быстро и имеет возможность удаления старых страниц (например, Яндекс, Google).
Особенности интернациональной индексации
- Если оптимизация сайта ведется для каждого поисковика индивидуально, т. е. для каждого из них есть своя копия страниц, чтобы их не сочли дублями, «скормите» каждому роботу свои страницы, пользуясь файлом robots.txt.
- Как узнать, сколько страниц сайта проиндексировано и какие именно? Почти все искалки имеют соответствующие команды.
- Поисковики при индексации могут споткнуться на фреймах, динамических страницах, Flash, JavaScript, Image Maps и т. д. Поэтому, когда используете что-то кроме статического HTML, подумайте об индексации.
Эксперимент без проблем
Если вы решились на эксперимент с поисковиком, чтобы не ломать потом голову над тем, что же означают полученные данные, следует строго придерживаться ряда правил.
- Нужно определить цель эксперимента до его начала. Должно быть ясно, какие данные следует получить и будет ли их достаточно для требуемых выводов.
- Все посторонние факторы, по возможности, должны быть исключены. Если, например, необходимо узнать, учитывает ли поисковик при вычислении релевантности теги «alt» изображений, то гораздо точнее будет создание и изучение двух идентичных во всем, кроме тегов alt, страниц, чем сравнение чужих страницы, отличающихся, в том числе, alt-тегами.
- Необходимо исключить все шумы, влияющие на результат поиска. Шумы, связанные с нестабильностью работы поисковиков, можно уменьшить, если проводить эксперимент ночью или в выходные дни. Измерения должны учитывать особенности алгоритмов поисковика. Например, когда подсчитывается число слов на странице, нужно исключать стоп-слова, игнорируемые поисковиком; когда подсчитывается число вхождений слова, надо учитывать все его грамматические формы, если поисковик понимает морфологию.
- Для выводов требуется статистическая достоверность. Нельзя делать выводы, исследовав пять сайтов или нерепрезентативную выборку сайтов (например, сайты, выдаваемые по одному запросу). Стоит ли данные накапливать быстро или лучше их получать в разные дни и разное время суток? Теоретически второй подход более корректен. На практике же встречается ситуация, когда поисковики, чтобы сбить с толку спамеров, немного меняют алгоритм вычисления релевантности ежедневно или даже чаще. Если известно о таком поведении поисковика, то лучше получить несколько порций данных в разные дни и обработать каждую их них отдельно.
- Методы анализа полученных данных должны быть адекватны данным, и учитывать, что реальные зависимости могут иметь сложный нелинейный характер. Например, оценка корреляции в неоднородной группе может быть очень неточной, как и в случае, когда зависимость нелинейна.
|
Опыты без взрывов
Можно ли, поставив эксперимент, узнать алгоритм поисковика или его часть? Конечно!
Метод деления пополам
Допустим, вас заинтересовал какой-либо показатель, влияющий на релевантность страницы, и вы предполагаете, что у него есть оптимум — меньшее значение делает страницу менее релевантной, а большее уже рассматривается как спам. Условно будем считать таким показателем процент ключевых слов на странице.
Для эксперимента создаются три страницы, в одной из которых процент ключевых слов близок к нулю, во второй — таков, что гарантированно будет сочтен спамом, а третья находится ровно посередине. Регистрируем и ждем индексации страниц. В зависимости от того, первая или вторая страница оказалась более релевантной, отсекаем половину исследуемого диапазона сверху или снизу. Повторяем до тех пор, пока оптимум не найден с нужной точностью.
Примечания:
- Страницы надо располагать на разных доменах, потому что большинство поисковиков в результатах поиска выдают сайты, а не страницы.
- Запрос, по которому ведется исследование, не должен быть редким, иначе даже при большой разнице в релевантности страницы могут оказаться в результатах поиска рядом.
- Некоторые поисковики проверяют текст на «естественность», поэтому соотношение числа глаголов, прилагательных, существительных и др. должно быть обычным. С этой целью можно использовать отрывок любого текста, в котором заменять своими словами нужные части речи.
Недостатков у метода два, но больших. Во-первых, никто не говорил про простой и линейный характер зависимости. Во-вторых, метод требует многократной переиндексации страницы, что обычно слишком долго, да и алгоритм поисковика тем временем может измениться. Как избежать недостатков?
Метод дроби
Зная, как и в предыдущем случае, примерный диапазон изменения процента ключевых слов, можно сделать не одну страницу, а 10-20, где процент ключевых слов изменяется с шагом, например, в 1%. Когда среди них станут известны 2-3 наиболее релевантные страницы, чтобы точнее выяснить оптимальный процент ключевых слов, можно будет добавить еще 10-20 страниц с шагом исследуемого показателя в 0,1%. Когда поисковики их зарегистрируют, в любой момент, взглянув на их положение в результатах, можно будет сказать, какой процент ключевых слов на данный момент оптимален. Недостаток, касающийся сложного характера зависимости, остался. Что же делать с ним?
Аналитические методы
В случаях, когда характер зависимости не ясен даже примерно, либо на исследуемые показатели нет возможности влиять, следует изучать зависимости на основе чужих сайтов. В такой ситуации резко возрастает влияние посторонних факторов и шумов, поэтому появляется необходимость использовать методы интеллектуального анализа данных (data mining, статистические пакеты и др.).
Учитывая сложность получения данных (например, веса страницы по алгоритму PageRank), на первом этапе сбор информации может касаться относительно небольшого числа страниц и запросов (десятки), для которых будет собрано максимальное число показателей, известных вам. После предварительного анализа информации можно выделить показатели, наиболее сильно связанные с интересующим вас параметром, и на следующих этапах собирать данные только о них. Эта тема достойна отдельной книги, и, увы, никак не может вместиться в объем статьи.
Выводы
Мы прошлись по основным алгоритмам поисковиков, посмотрели, как надо оптимизировать сайт, где брать информацию и с чего начинать. Что дальше? Мой совет остается неизменным: давайте думать и работать, и превосходный результат обязательно появится!
P. S. Благодарю Илью Сегаловича (Яндекс) за ценные замечания по статье.
Материалы по теме:
Александр Садовский
Источник: Исследования и статистика
|
|